主成分分析
主成分分析(Principal Component Analysis,PCA)是研究如何通过原始变量的少数几个线性组合来解释原始变量绝大多数信息的多元统计分析方法。在尽可能地保留原始变量信息的前提下进行降维,从而简化问题的复杂性,抓住问题的主要矛盾。 该方法主要基于众多原始变量之间有一定的相关性(即共线性),则必然存在着起支配作用的共同因素这一想法,来对原始变量协方差矩阵或相关系数矩阵内部结构进行研究。
使用前提
开展PCA一般需要满足以下前提条件:
- 原始数据的变量数目较多,或有数据降维的需求,否则做主成分分析没有意义。
- 原始数据各个变量之间的共线性或相关关系较强,如果原始变量之间的线性相关程度很小,它们之间不存在简化的数据结构,这时进行主成分分析实际是没有意义的。
- 在应用PCA之前,需要对其适用性进行统计检验,检验方法有
- KMO 抽样适合性检验(Measure of Sampling Adequacy,检验原始变量之间的相关系数和偏相关系数的相对大小)
- 巴特利特(Bartlett)球形检验(检验原始变量间的相关程度,即共线性程度)
- 等等。
PCA使用前提摘自主成分分析(Principal Component Analysis)——理论介绍
通俗理解主成分分析
假如原始数据中总共有 100 个原始变量,为方便分析及解释,我们希望把这 100 个原始变量给“浓缩”一下。注意,“浓缩”体现出主成分分析的精髓:
- 浓:原始变量蕴含的信息,在操作中要最大程度地保留;
- 缩:维度要降低。
我们想要尽可能地保留原始数据中的信息(因为降维不可避免地会造成信息的丢失,想象从 3 维空间到 2 维空间)什么时候信息的“利用率”最高呢?答案是正交的时候。变量间相互正交,可以理解为不同变量所蕴含的信息不重复,每个变量中蕴含的信息都是独一无二、无可替代的。
信息这个词有点抽象,其实有个概念可以很好地量化“信息”这个词:方差。变量的“方差”所蕴含的是“信息量”(理解:变异程度越大,其中所含信息就越多)
所以:思路清楚了:把原始变量组合成方差大且正交的新变量即可。
具体操作
我们从包含变量方差信息的矩阵——协方差矩阵入手。
既想降维,减少变量个数,又想尽可能地保留信息:把方差大的几个原始变量组合起来不就好了。
对协方差矩阵进行特征值分解(实对称矩阵必可相似对角化)不就好了。取最大的几个特征值所对应的特征向量作为主成分即可。
但是特征值分解有个问题,只适用于方阵,且更致命的是:计算量成本巨高。
所以便引入使用奇异值分解的方法。详见推文
关于奇异值分解,其思想跟 LoRA (针对LLM的一种轻量级微调技术)相似:通过“低秩近似”以减小算法上的开支:
例如一个 985 × 211 的矩阵,有 20w+ 个元素需要计算;通过低秩近似,用 985 × 10 乘 10 × 211,便只需要计算不到 2w 个元素
特征值分解和奇异值分解两种方法,都能达到目的。但途径不同,各有千秋。
使用协方差矩阵还是相关系数矩阵 ?
各变量量纲差不多时,使用协方差矩阵即可。反之则使用相关系数矩阵(多了一步标准化的操作)
个人感觉无脑使用相关系数矩阵即可,不知道协方差矩阵在相关系数矩阵面前有什么优势?如有知道的朋友,还请指教。
因子分析
面对主成分分析中主成分难以解释的问题,因子分析,被当做主成分分析的推广和发展,得到广泛应用。
因子模型
$$x = \mu + Af + \varepsilon$$
式中 f = $(f_1, f_2, \cdots, f_m)’$ 为公共因子向量,$\varepsilon = (\varepsilon_1, \varepsilon_2, \cdots, \varepsilon_p)’$ 为特殊因子向量,$A = (a_{ij}): p \times m$ 称为因子载荷矩阵。
模型假设:
- 公共因子之间不相关;
- 特殊因子之间不相关;
- 公共因子和特殊因子之间不相关
下面的任务便是:估计因子载荷矩阵 $A$ 和公共因子向量 $f$。
可以对比一下回归分析中 $Y=X\beta+\varepsilon$ 主要估计的是 $\beta$ ,$X$ 是已知的观测值。
因子载荷矩阵常用的估计方法
主成分法:(直接像 PCA 一样进行特征分解,又称谱分解)、主因子法、极大似然法
主成分分析与因子分析的区别与联系
“降维”,顾名思义就是降低数据维度(数据维度 = 原始变量个数)。
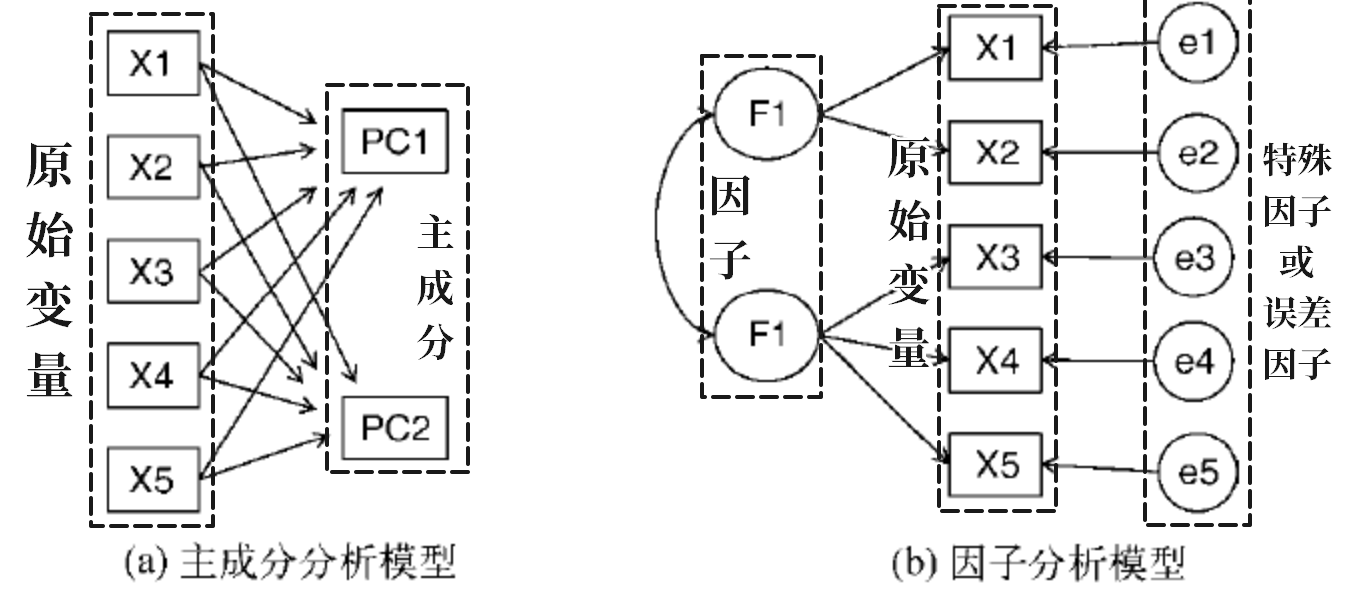
主成分分析和因子分析使用的都是“降维”的思想,但两者“降维”的思路不一样,两者“降维”的思路差异,也就造成了两者的“可解释性”差异:
- 主成分分析是通过将原始变量进行线性组合(称为主成分)来达到“降维”的目的,可解释性弱;
- 而因子分析则是先提炼因子,再用所提炼的因子来表达原始变量,可解释性强。
举个例子:假设我们收集了 100 名学生在 4 门课程(语文、数学、地理、生物)中的考试成绩,我们希望找出数据的潜在结构,减少变量维度,便于分析。
- 主成分分析(这里不太严谨,因为没保证正交):
- 理科主成分 = 数学 + 0.7 生物 + 0.4 地理;
- 文科主成分 = 语文 + 0.3 生物 + 0.6 地理。
- 因子分析:
- 先设定因子:文科因子和理科因子
- 语文 = 1 × 文科因子 + 0 × 理科因子
- 数学 = 0 × 文科因子 + 1 × 理科因子
- 生物 = 0.3 × 文科因子 + 0.7 × 理科因子
- 地理 = 0.6 × 文科因子 + 0.4 × 理科因子
原始变量与主成分/因子间的关系
主成分分析:相关系数和载荷
$x_i = t_{i1}y_1 + t_{i2}y_2 + \cdots + t_{ip}y_p, \quad i = 1, 2, \ldots, p$
两个指标:相关系数 $\rho(x_i, y_k)=\frac{\sqrt{\lambda_k}}{\sqrt{\sigma_{ii}}}t_{ik}$ 和载荷(即主成分表达式中的系数)
- 相关系数:单变量角度,忽略了其它原始变量的前提下某原始变量与某主成分之间的关系;
- 载荷:多变量角度,考虑到了其它原始变量在场的情况下某原始变量与某主成分之间的关系。
所有主成分对某原始变量的贡献率:m 个主成分 $y_1, y_2, …, y_m$ 对原始变量 $x_i$ 的贡献率 $\rho_{i \cdot 1, \cdots, m}^2 = \sum_{k=1}^{m} \rho^2(x_i, y_k) = \sum_{k=1}^{m} \frac{\lambda_k t_{ik}^2}{\sigma_{ii}}$;
在解释主成分时,看哪个呢?马哲告诉我们:既需要考察相关系数,又需要考察载荷。
因子分析:因子载荷矩阵和因子得分矩阵
因子载荷矩阵是一个 变量×因子 的矩阵,其中元素即各个原始变量的因子表达式的系数,表达提取的公因子对原始变量的影响程度。
通过因子载荷矩阵可以得到原始指标变量的线性组合,如 $X_1=a_{11}*F_1+a_{12}*F_2+a_{13}*F_3$, 其中 $X_1$ 为指标变量 1,$a_{11}, a_{12}, a_{13}$ 分别为与变量 $X_1$ 在同一行的因子载荷,$F_1, F_2, F_3$ 分别为提取的公因子;
- 因子载荷矩阵 $A$ 中的元素 $a_{ij}$ :表示 $x_i$ 与 $f_j$ 之间的协方差或相关系数(取决于是否标准化)
- 因子载荷矩阵 $A$ 的行元素平方和:反映公共因子对 $x_i$ 的影响,称为共性方差。特殊因子对 $x_i$ 的方差贡献则称为 $\sigma_i^2$ 特殊方差。
- 因子载荷矩阵 $A$ 的列元素平方和:可视为公共因子 $f_i$ 对 $x_1, x_2, …, x_p$ 的总方差贡献,是衡量公共因子 $f_i$ 重要性的一个尺度。
- 因子载荷矩阵 $A$ 的所有元素平方和:公共因子 $f_1, f_2, …, f_m$ 对总方差的累计贡献。
公共因子的估计值, 称为因子得分 (factor scores)
因子得分矩阵是一个 样本×因子 的矩阵,表示个体在潜在因子上的得分。它显示了每个观测对象(样本)在各个因子上的得分。因子得分反映了每个观测对象在因子上的位置或表现,数值越大,表示该对象在该因子上的得分越高。
因子得分可以通过两种方法:加权最小二乘法和回归法(之所以称为回归法,是因为在回归分析中,条件均值被称之为回归函数)对不可观测的随机变量 $f_1, f_2, …, f_m$ 的取值进行估计(但不算是参数估计)
通过一个例子来加深理解:

关于旋转💫
主成分分析和因子分析中的旋转,就是让各变量在单主成分(因子)上有高额载荷,而在其它主成分(因子)是只有小到中等的载荷。其目的是为了提高可解释性。
- 让每个变量对某个主成分/因子的贡献更清晰(即让因子载荷更接近 0 或 1,减少多个因子共享同一变量的情况)。例如
- 某主成分 = $0.6X + 0.5Y + 0.5Z + …$ 有些含糊
- 某主成分 = $0.9X’ + 0.1Y’ + 0.05Z’ + …$ 更清晰明了
- 让主成分/因子更加符合实际意义(即调整主成分/因子,使其更接近数据中方差较大的方向,同时减少信息混杂)。
可以看作一种对“主成分”或“因子”的优化。
主成分分析中也可以旋转,但一般情况下并不需要旋转,因为既然选择了主成分分析,一般都不会太在意主成分的“可解释性”。
时序数据能进行 PCA 和因子分析吗?
绝大多数情况都不能,因为时间序列数据在绝大多数情况下都存在自相关性,不是简单随机样本 (要求 iid),样本协方差矩阵 (相关系数矩阵) 不是总体协方差矩阵 (相关系数矩阵) 的无偏估计,贸然应用样本协方差矩阵 (相关系数矩阵) 会产生较大偏差。
如处理后的数据消除了自相关性,则可考虑进行 PCA 和因子分析。
聚类分析
聚类分析(Cluster Analysis)是一种无监督学习技术,主要用于将数据样本划分成多个类别或簇(Cluster),使得在同一簇内的数据相似性较高,不同簇之间的数据相似性较低。
- 距离度量:闵考夫斯基距离(绝对值距离(又名曼哈顿距离)、欧氏距离、切比雪夫距离)、兰氏距离(加权版的曼哈顿距离)、马氏距离(协方差距离) 可参考其它推文链接1、 链接2
- 相似系数:夹角余弦、相关系数
- 不同的聚类方法: 不同聚类方法效果对比图
- 系统聚类法(层次聚类法)
- 凝聚的层次聚类:最短距离法、最长距离法、类平均法、重心法、中间距离法、离差平方和法(Ward’s method).
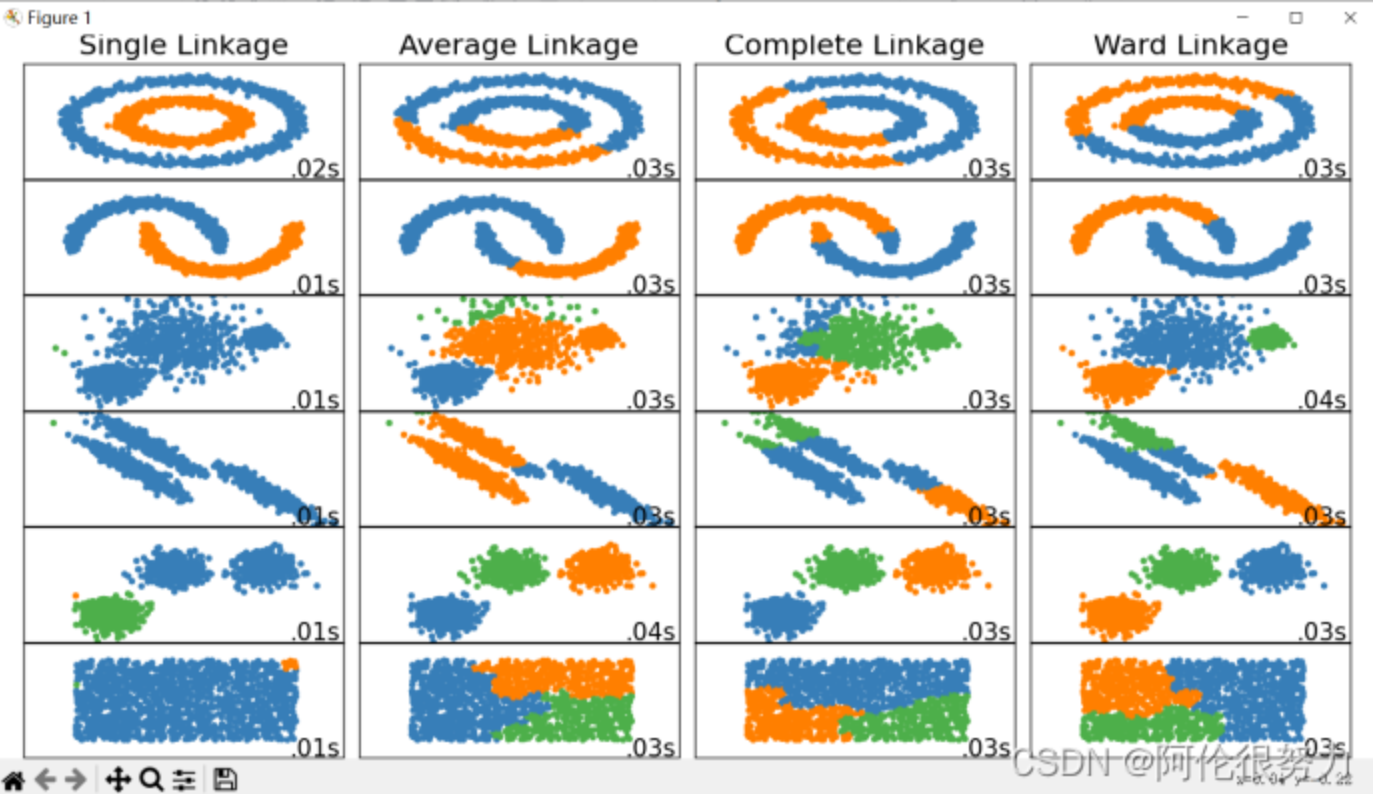 上图图源 CSDN @阿伦很努力 推文
上图图源 CSDN @阿伦很努力 推文 - 分裂的层次聚类:略,分裂其实就和凝聚反过来一样
- 凝聚的层次聚类:最短距离法、最长距离法、类平均法、重心法、中间距离法、离差平方和法(Ward’s method).
- 动态聚类法(逐步聚类法,西瓜书中称为原型聚类):K-means(初值敏感)、K-means++(随机初值,轮盘法更新聚类中心)、bi-kmeans(优化局部最优问题)。K-Means 简单快速,适用大数据集,但只适用于平均值能被定义的情形,且初值敏感。
- 基于密度的聚类方法:DBSCAN
- 新方法:核聚类、谱聚类、量子聚类等
- 系统聚类法(层次聚类法)
{kind=link}
用目测法在主成分得分图上可以进行直观的聚类,其中包含着正规聚类方法所反映不出的丰富信息,由此或许可以得到比正规聚类方法更为合理的聚类结果。
判别分析
判别分析(discriminant analysis)属于“有监督学习”方法,从所谓“训练样本”经过分析计算得到一个判别规则,对新的数据可以利用判别规则判断新数据观测的类属。训练样本中既有用来分类的解释变量(自变量),又有真实的类属(标签,因变量)。
常用判别分析方法有距离判别、Fisher判别和Bayes判别,Logistics回归也经常用在判别问题中(尤其是两类的判别),分类树也是用于判别的方法。
-
距离判别:根据待判定样本与已知类别样本之间的距离远近做出判别。典型算法如:K最近邻(K-Nearest Neighbor,简称 KNN,“邻居是啥,我就是啥”)
-
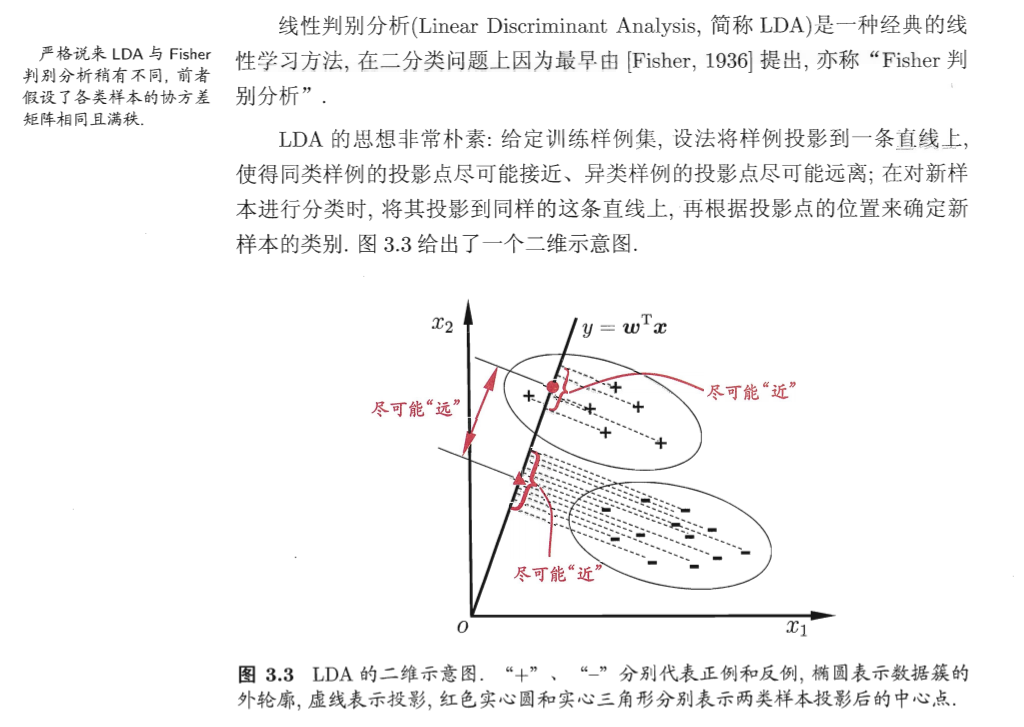
费希尔判别:通过“投影”简化问题。(与 SVM 的思想刚好相反,SVM 是通过超平面升维)。如二分类问题上的线性判别分析(Linear Discriminant Analysis,简称LDA)。 线性判别分析LDA 详见 [[机器学习 Machine Learning]]
-
贝叶斯判别:最大后验概率法、最小期望误判代价法。典型算法:朴素贝叶斯分类器(Naive Bayesian Classification),哪个类别后验概率大,就属于哪个类别(拉普拉斯平滑解决特征未出现在训练集导致后验概率为 0 的问题) ^dkbbsu
当标签(因变量)只有两个类时,判别分析问题与假设检验问题有相似之处。
- 假设检验问题更强调统计推断的严谨性(拒绝原假设的理由一定要充分);
- 两类的判别问题并不强调某个类别,或者按照先验概率、损失函数对不同类别施加不同的影响。
- 可以这样理解:假设检验是有“偏向”的,而判别分析是“平等”的 [[九阳真经 - 假设检验篇#假设检验的精髓:不平衡(Imbalance)]]
线性判别分析与其他分类算法有以下联系:转载
- 与逻辑回归的联系:逻辑回归是一种基于概率模型的分类算法,它可以看作是线性判别分析在多元正态分布假设下的一种特殊情况。逻辑回归假设输入变量之间是独立的,而线性判别分析则不作这一假设。
- 与支持向量机的联系:支持向量机是一种通过最小化损失函数来训练分类器的算法。在线性情况下,支持向量机可以看作是线性判别分析在不使用正态分布假设的情况下的一种特殊情况。
- 与决策树的联系:决策树是一种基于树状结构的分类算法,它可以自动选择特征并构建分类器。决策树与线性判别分析的主要区别在于决策树不需要任何假设,而线性判别分析则需要正态分布假设。
- 与朴素贝叶斯分类器的联系:朴素贝叶斯分类器是一种基于贝叶斯定理的分类算法,它假设输入变量之间是独立的。朴素贝叶斯分类器与线性判别分析的主要区别在于朴素贝叶斯分类器不需要正态分布假设。
区分 K-Means 和 KNN 两种不同算法!K-Means 用于聚类分析;而 KNN 用于判别分析。
...