- 德国学者 Gauss (1777‐1855) 于 1809 年提出最小二乘法。
- 英国遗传学家 Galton (1822‐1911) 于 1886 年发表关于回归的开山论文 《遗传结构中向中⼼的回归》Regression towards Mediocrity in heredity structure)。[[统计学史#^tp89te]]
回归分析是处理变量之间的相关关系的⼀种统计⽅法和技术。
- 相关分析:⽤⼀个指标 (相关系数) 来表明现象间相互依存关系的密切程度。以现象之间是否相关、相关的⽅向和密切程度等为研究内容,不区分⾃变量和因变量,不关⼼相关关系的表现形态。
- 回归分析:对具有相关关系的现象,根据其相关关系的具体形态,选择⼀个合适的数学模型 (回归⽅程) 来近似地表达变量间的平均变化关系。
- 相关分析是回归分析的基础和前提;回归分析是相关分析的深⼊和继续。
- ⼴义的相关分析包括回归分析。
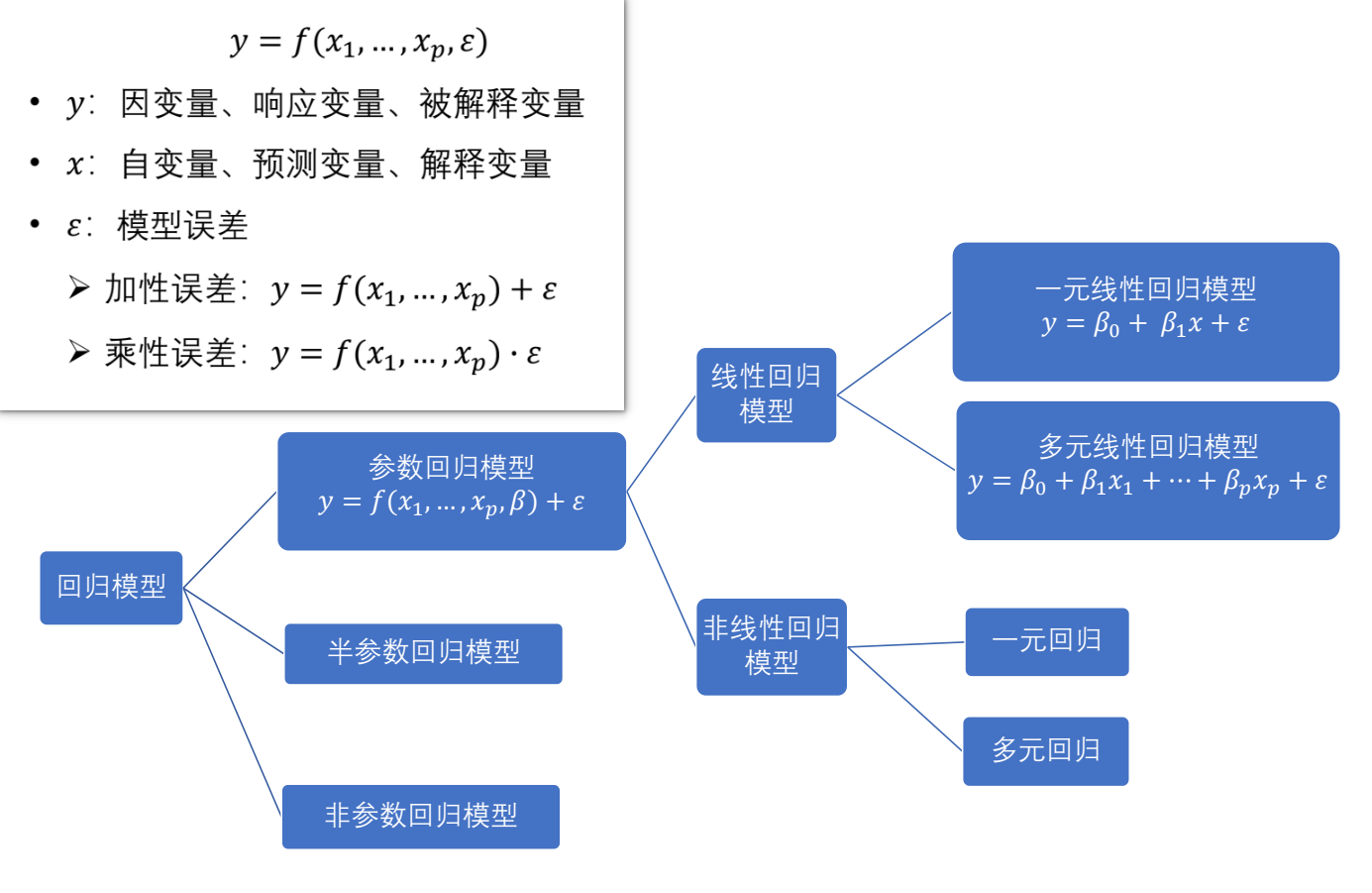
模型假设
- 样本回归模型 $y_i=\beta_0+\beta_1x_i+\varepsilon_i$.
- 理论回归模型 $y=\beta_0+\beta_1x+\varepsilon$.
- 经验回归方程 $\hat{y}=\hat{\beta}_0+\hat{\beta}_1x$.
- 回归模型 $E(y|x)=\beta_0+\beta_1x$ 从平均意义上表达了变量 $y$ 与 $x$ 之间的统计规律性
- 如何理解回归模型中的条件期望?在给定解释变量 $X$ 取特定值 $x$ 时,被解释变量 $Y$ 的平均值。
回归分析的基本假定:
- 因变量和自变量之间存在线性关系 2. 观测值应该相互独立,避免自相关问题 3. 残差应该近似服从正态分布,这一假定有助于进行统计推断和构建置信区间 4. 残差的方差在不同自变量取值的情况下应该大致相等,避免异方差问题 5. 自变量之间应该是线性无关的,避免多重共线性问题
可以通过残差分析、散点图、Q-Q图等方法来检验这些基本假定的成立程度

⚠️G-M 假设不要求扰动项服从正态分布!
在高斯马尔科夫条件下,最小二乘估计是在所有线性无偏估计中具有最小方差的,被称为BLUE(Best Linear Unbiased Estimators)
正态性假设: $\varepsilon_i \sim N(0, \sigma^2)$, 且 $\varepsilon_i$ 间相互独立。
正态假定下 MLE 与 OLSE 等价,MLE最大化似然函数,OLSE最小化损失函数。
⼀元线性回归中⾃变量和残差的关系:在⼀元线性回归模型中, ⾃变量 (X) 和残差 (ε) 理论上应该是独⽴的。残差代表了实际观测值与通过回归线预测值之间的差异。如果⾃变量和残差不独⽴,可能表明模型中存在遗漏变量或⾮线性关系没有被正确模型化。
违背基本假设的几种情况
1 多重共线性
-
定义:多变量线性回归中,变量之间由于存在高度相关关系而使回归估计不准确。
-
问题:$\beta$ 方差 $\sigma^2(X’X)^{-1}$ 偏大,估计精度低,不稳定,t 统计量↓,不易拒绝 $H_0$.
-
诊断:容忍度 $1-R_j^2$ <0.1、方差扩大因子 $VIF_j=\frac{1}{1-R_j^2}≥10$、条件数 $=\frac{\lambda_{max}}{\lambda_{min}}≥100$、直接看特征根(是否接近 0)
-
解决⽅法:可以通过以下方法来解决:
- 变量选择;
- 使⽤主成分回归(PCR),$X$ 中有多重共线性的变量,那就不使用 $X$ 来进行回归分析,转而使用 $X$ 对应的主成分矩阵。
- 偏最小二乘法:相较于通过寻找响应和独立变量之间最小方差的超平面,偏最小二乘法通过投影预测变量和观测变量到一个新空间来寻找一个线性回归模型。
- 岭回归($X’X$ 不可逆?那就加上一个正则项 $X’X+kI$ 这样就可逆了),代价是:有偏。通过岭迹图来确定 $k$ 值
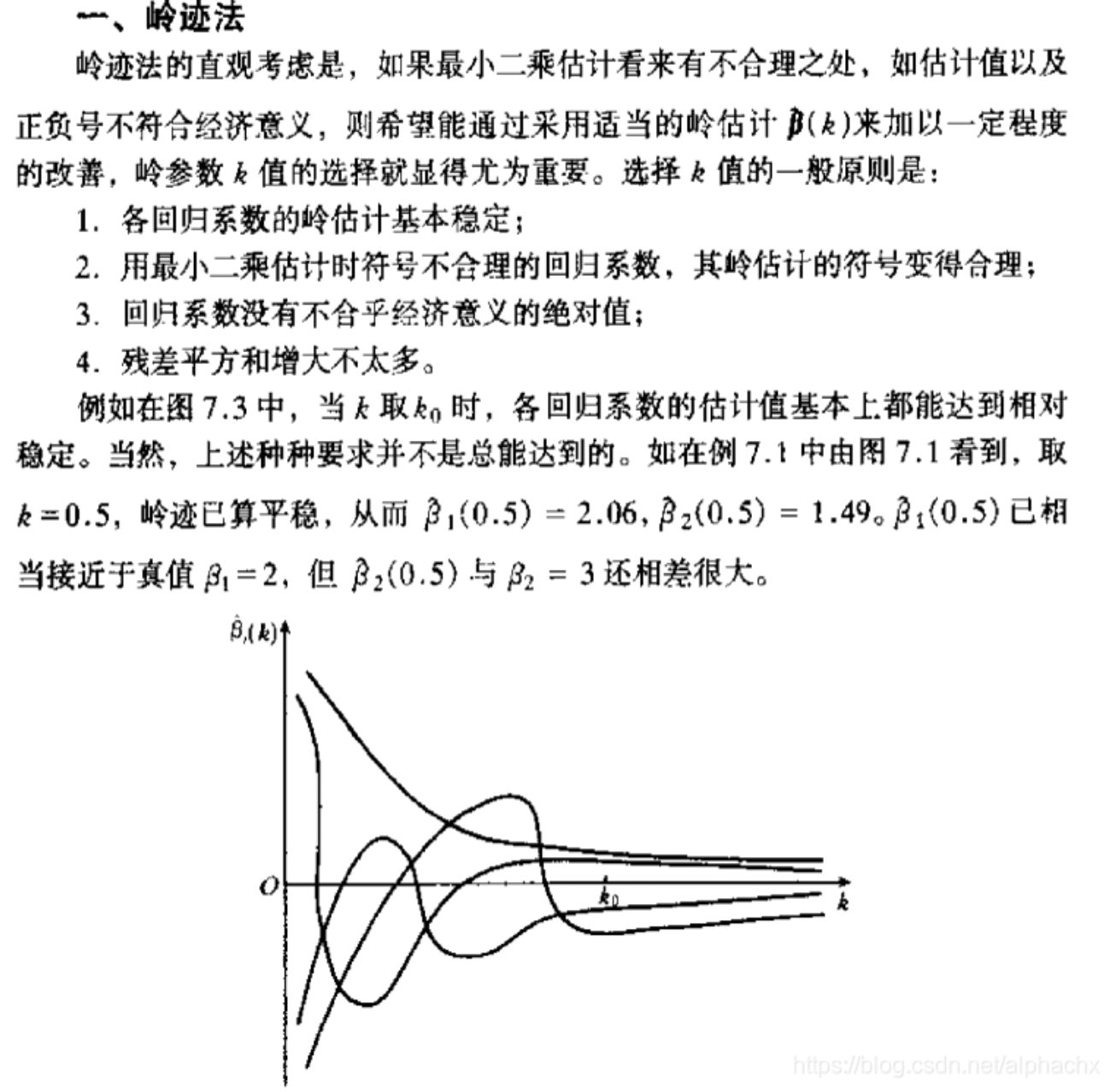
- Lasso 回归。详见下图:
 图源博客园博文
图源博客园博文
-
注意:不是说一个模型有多重共线性情况,那这个模型就完全不行。如果说是利用模型去做经济结构分析,那么要尽可能避免多重共线性;而如果说只是利用模型去做经济预测,只要保证自变量的相关类型在未来时期中保持不变,即使回归模型中含有严重多重共线性的变量,也可以得到较好的预测结果。
2 异⽅差性
- 问题:虽仍是无偏估计,但不是 MVUE;显著性检验失效,回归方程应用效果不理想。
- 诊断:绘制残差图、斯皮尔曼检验
- 解决⽅法:可以使⽤加权最小二乘法(WLS)或对变量进⾏变换(BOX-COX)。
3 ⾃相关
- 产生原因:遗漏关键变量、经济变量的滞后性、回归函数的错误、蛛网现象、不恰当的数据预处理方式(如差分变换)
- 问题:t 值↑,易犯拒真错误;估计值不再是 MVUE;MES 严重↓
- 诊断:绘制 $e_i, e_{i-1}$ 散点图、自相关系数绝对值接近 1、DW 值离 2 的距离越远自相关越严重。
- 解决⽅法:迭代法、差分法、广义最小二乘法(GLS)、时间序列模型(如 ARIMA)或对数据进行BOX-COX 变换。
4 ⾮线性关系
- 问题:如果因变量与⾃变量之间的关系是⾮线性的,线性回归模型⽆法准确描述这种关系。
- 解决⽅法:可以使⽤⾮线性回归模型,或者对变量进⾏变换(如对数变换、多项式回归)。
5 数据量不⾜
- 问题:如果样本量太少,回归模型的参数估计可能不准确,模型容易过拟合。
- 解决⽅法:增加数据量,或者使⽤正则化⽅法(如 Lasso 回归)来防⽌过拟合。
6 忽略重要变量
- 问题:如果模型中遗漏了重要的⾃变量,会导致回归系数估计有偏。
- 解决⽅法:通过领域知识或变量选择⽅法(如逐步回归)来识别重要变量。
7 异常点、高杠杆点与强影响点
- 注意:异常点不一定是强影响点,强影响点也不一定是异常点、高杠杆点不一定是强影响点,强影响点也不一定是高杠杆点
- 问题:异常值会对回归模型的拟合产⽣较⼤影响,导致模型失真。
- 解决⽅法:可以通过剔除异常值或使⽤稳健回归⽅法。
- 诊断: 参考
- 判断异常点,异常值点:对既定模型偏离很⼤的数据点
- 标准化残差 $ZRE_i=\frac{e_i}{\hat{\sigma}}$ 绝对值>3
- 学生化残差 $SRE=\frac{e_i}{\hat{\sigma}\sqrt{1-h_{ii}}}$ 绝对值>3, 相较于标准化残差,学生化残差剔除了高杠杆值的影响;
- 判断高杠杆点:杠杆值 $h_{ii}=\frac{1}{n}+\frac{(x_i-\bar{x})^2}{\sum_{j = 0}^{n} (x_j-\bar{x})^2}$, 高杠杆点≠强影响点≠异常点,在⾃变量空间中远离数据中⼼的点,有把拟合直线拖向⾃⼰的倾向,称之为⾼杠杆点
- 判断强影响点:库克距离 $D_i=\frac{\sum_{j = 0}^{n} (y_j-y_{j(i)})^2}{p ·MSE}$ >0.5, 度量去除某一数据点后其它样本拟合值的变化。强影响点是对统计推断产⽣较⼤影响的数据点,删除该点会导致拟合模型的实质性变化,如参数估计值、拟合值或检验值发⽣较⼤变化。库克距离是一个综合指标,结合了杠杆值和残差大小,用来评估数据点对回归系数估计的整体影响。
- 判断异常点,异常值点:对既定模型偏离很⼤的数据点
变量选择中评价模型的指标
- 自由度调整复决定系数越大越好;
- AIC 和 BIC:这两个准则都是基于似然函数,考虑了模型复杂度的惩罚。在⽐较多个模型时,AIC 和BIC 较⼩的模型被认为更优; ^grw9h5
- $C_p$ 统计量越小越好;
- 调整 $R^2$:对 $R^2$ 进⾏调整,考虑了模型中变量的数量。在模型中添加更多变量时,即使这些变量对模型的贡献很⼩,$R^2$ 也可能会增加。调整后的 $R^2$ 提供了⼀个更为准确的衡量标准。
- 残差图分析:通过观察残差(实际值与预测值之差)的分布情况,可以评估模型是否满⾜线性回归的假设,例如残差的独⽴性、正态性和⽅差⻬性。
- 下面这几个有些许风险:选择解释变量时不应以 SSE 为标准,因为变量↑,SSE 一定↓(想象过拟合,调整 $R^2$ 就解决了这个问题),可以看看各变量系数是否显著。
- 均⽅误差:计算模型预测值与实际值差值的平⽅的平均值。MSE 越⼩,模型的预测准确度越⾼ 。
- 均⽅根误差:MSE 的平⽅根。RMSE 是衡量模型预测误差的常⽤标准,越⼩表示模型预测越准确。
- 平均绝对误差:计算模型预测值与实际值差值的绝对值的平均值。MAE 提供了预测误差的另⼀种衡量,对异常值的敏感度低于 MSE。
- 决定系数:衡量模型预测值的变异性占总变异性的比例,值范围从 0 到 1。$R^2$ 值越接近 1 ,表示模型解释的变异性越⼤,拟合度越好。
选择合适的评估⽅法取决于具体的研究目的和数据特性。通常,结合使⽤多种评估指标可以更全⾯地了解回归模型的性能。

❗注意弄清楚 F 检验统计量和 $R^2$ 的表达式: $F=\frac{MSR}{MSE}$, $R^2=\frac{SSR}{SST}$
误差、残差与偏差
- 误差:观测值与真实值的偏离,如多次测量取平均值中的“测量误差”;
- 残差:观测值与模型估计值的偏离,可以理解为随机噪声;
- 偏差:观测值与模型估计值的偏离,排除噪声的影响,偏差是模型无法准确表达数据关系导致,比如模型过于简单,非线性的数据关系采用线性模型建模等,反映模型本身的精确度。
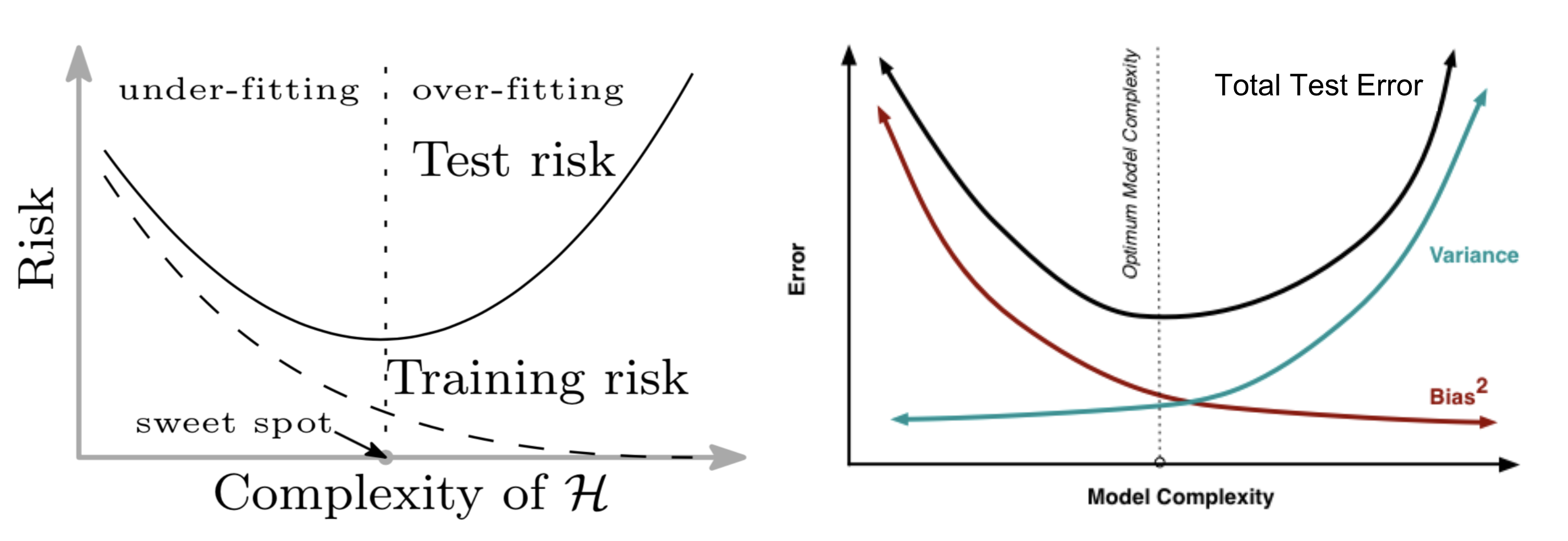 注:左图来自
注:左图来自针对欠拟合和过拟合的处理方式如下:
- 欠拟合:偏差过大,做特征工程、减小(弱) 正则化系数;
- 过拟合:方差过大,可增加样本、减少特征、增加(强)正则化系数;
过拟合会导致方差偏大,核心原因在于模型对训练数据的依赖过强,从而导致其泛化能力下降。在偏差-方差分解(Bias-Variance Tradeoff)中:$\mathbb{E}[(\hat{y} - y)^2] = \text{Bias}^2 + \text{Variance} + \text{Noise}$
过拟合时,模型在训练集上的偏差几乎总是很小,而在验证集上,偏差可能不明显,但高方差会导致测试误差增大。
过拟合会导致方差偏大的本质原因是模型对训练数据的学习过度,使得它对新数据的预测波动性增加,从而导致测试误差的不稳定性。这也就是为什么在深度学习或机器学习任务中,我们通常需要正则化(如L1/L2正则化、Dropout)、数据增强或早停(Early Stopping)等方法来降低方差,提高泛化能力。
残差分析中的 QQ 图:用于对残差进行正态性检验(P-P图和Q-Q图都是用于检验样本的概率分布是否服从某种理论分布。)
样本决定系数 $R^2$
$R^2 = \frac{SSR}{SST} = \frac{\sum_{i=1}^{n} (\hat{y}_i - \overline{y})^2}{\sum_{i=1}^{n} (y_i - \overline{y})^2}$. 它指的是回归平方和占总平方和的比重, 表示自变量对因变量随机性的解释比例, 同时也反映了自变量和因变量的线性相关性强弱。
区间估计 &区间预测

在回归分析中,如何处理无序变量?
分两种情况:自变量是无序变量、因变量是无序变量(Logistic 回归,在线性回归的基础上加了一个 Sigmoid 函数(非线形)映射,使得逻辑回归称为了一个优秀的分类算法)。
下面详细写写自变量是无序变量的情形:
处理无序变量,核心思想就是“编码”,参考 解决(几乎)任何机器学习问题:处理分类变量篇(上篇)
设置哑变量。哑变量:又称为虚拟变量、虚设变量或名义变量。对于有n个分类属性的自变量,通常需要选取1个分类作为参照,因此可以产生n-1个哑变量。哑变量即 One-Hot Encoding!
One-Hot Encoding:这是最基础也是最常见的转换手段之一。它会给每个类别创建一个新的二进制列,并标记是否存在该值(0 或者 1)。然而这种方法可能会导致维度爆炸的问题,在类别过多的情况下生成大量的新特性。
下面的其它 Encoding 方法先浅浅涉猎,在归纳机器学习的时候再深入了解。
- Binary Encoding;
- BaseN Encoding;
- Target Encoding / Mean Encoding;
- Feature Hashing (Hash Trick) .
...